Turn Trapped PDF data Into Actions: Reform's Advanced Document Understanding
Reform • 2024-06-06
How Reform is solving one of the most fundamental problems in supply chain; paper.
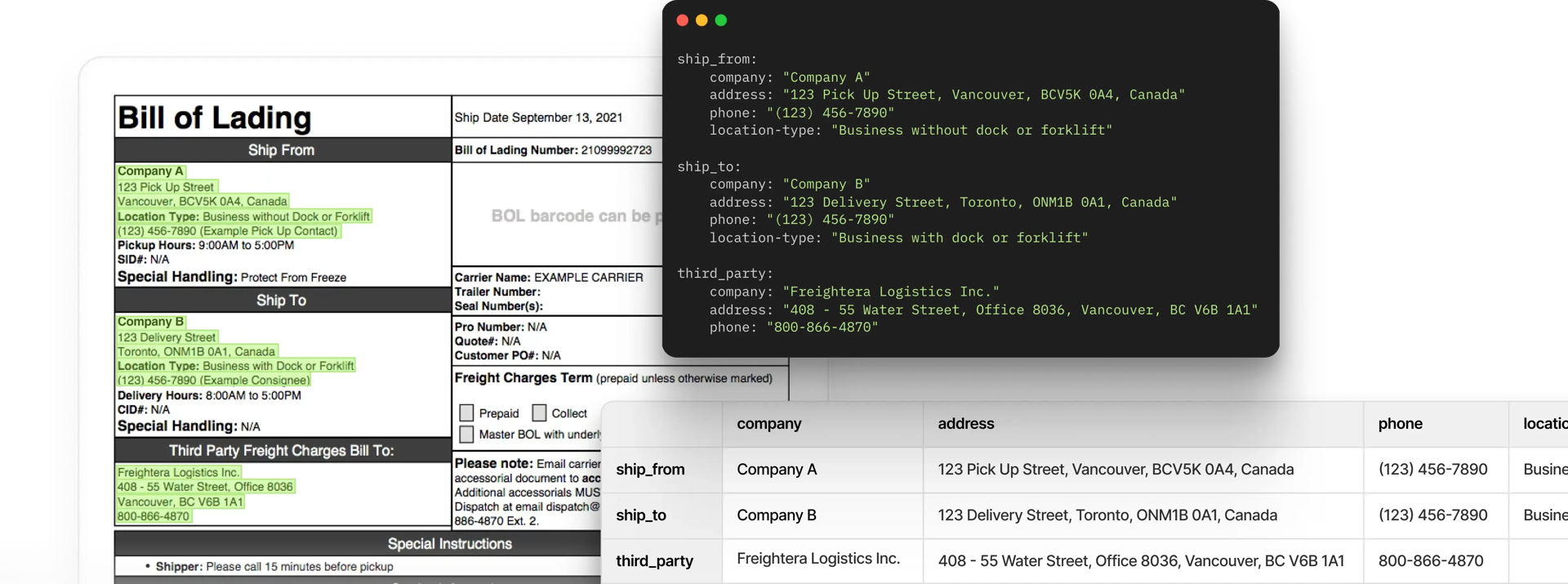
In the ever-evolving landscape of technology, it could feel like we’ve peaked. There’s a software product for every business process, every industry, and every use case. Yet, despite the remarkable advancements in various industries, one persistent challenge continues to plague logistics service providers: the laborious task of processing PDF documents. Whether it's invoices, bills of lading, purchase orders, or packing lists, the logistics sector remains entrenched in a world where manual extraction and interpretation of data from PDFs reign supreme.
Whether you are a freight forwarder, a broker, a factor, or a customs broker, your business relies heavily on manual document review and analysis. You could be auditing invoices, digitizing packing lists, filing for customs, or populating your TMS, the source of truth for 90% of your data is paperwork.
At Reform, we understand the frustration and inefficiency inherent in this process. That’s why we introduced our AI document parsing and understanding - an effort to put an end to this once and for all.
Unlike traditional PDF parsers that require extensive training data, complex rules, and setup procedures, our product offers a seamless out-of-the-box experience, making tedious data extraction a thing of the past. Our technology leverages advanced pre and post-processing techniques, coupled with proprietary spacial document understanding that enable us to handle the most tedious document formats that contain handwriting and complex tables.
In this article, we dive into how simple it is to use Reform to extract clean, usable data from PDFs.
Once you’re logged into Reform, you can simply drag and drop a PDF and get started by defining the Shape of the data you want to extract. A Shape is simply a description of the different data fields you are interested in. When building this product, it was super important for us that the experience is as human as possible, that’s why all you need to do is describe the fields you’re interested in using plain English.
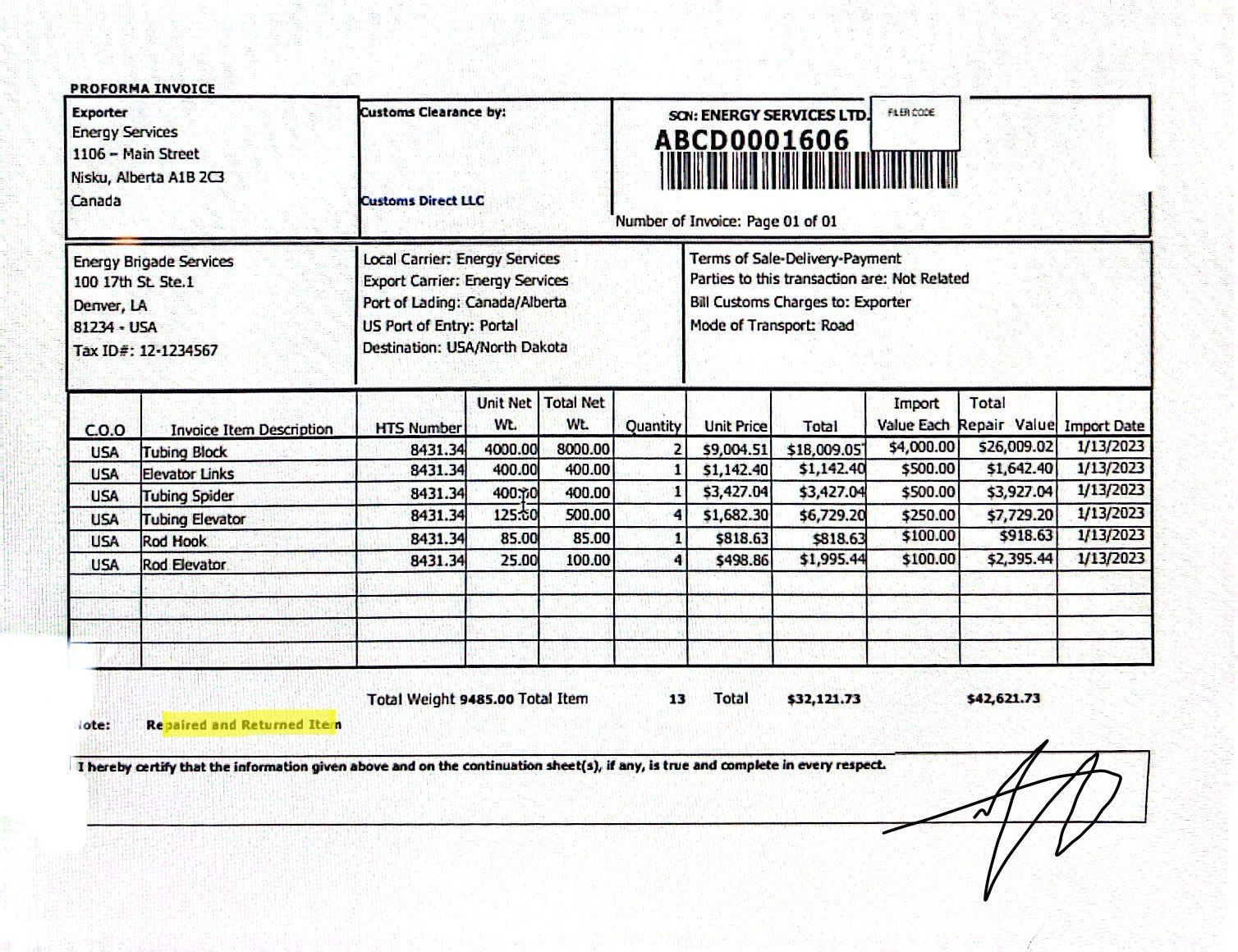
Let’s take the document above as an example. As you can see, the document is blurry, is a scan, and contains handwriting. Here are some data fields I might be interested in:
- Exporter data
- Carrier Data
- Line-items and totals
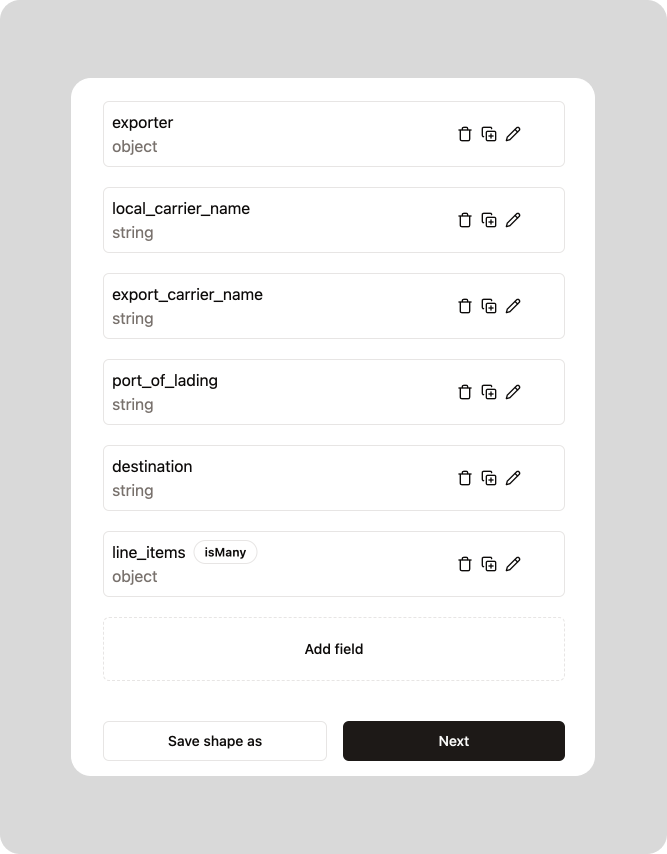
On Reform, the Shape that defines those data fields will look something like so:
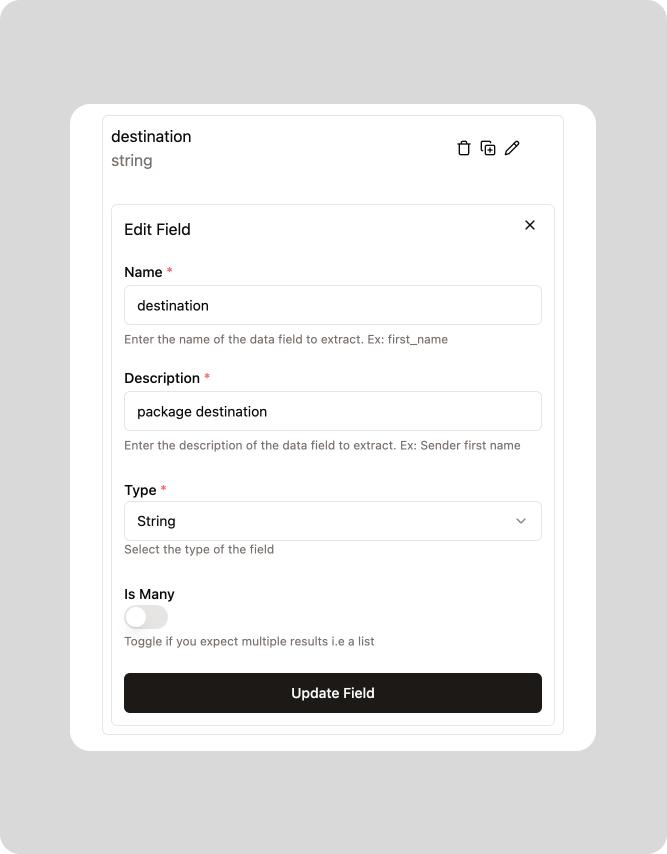
And if we expand one of those fields, you’ll see that we use simple language to describe the field:
And that’s it! This is all the setup that you need to do to get the desired data from the document and in a format that you can later use. What Reform will return is a simple, clean data object that you can write into a 3rd party system, a CSV file, or a spreadsheet. Here’s what the extraction result can look like for the document above:
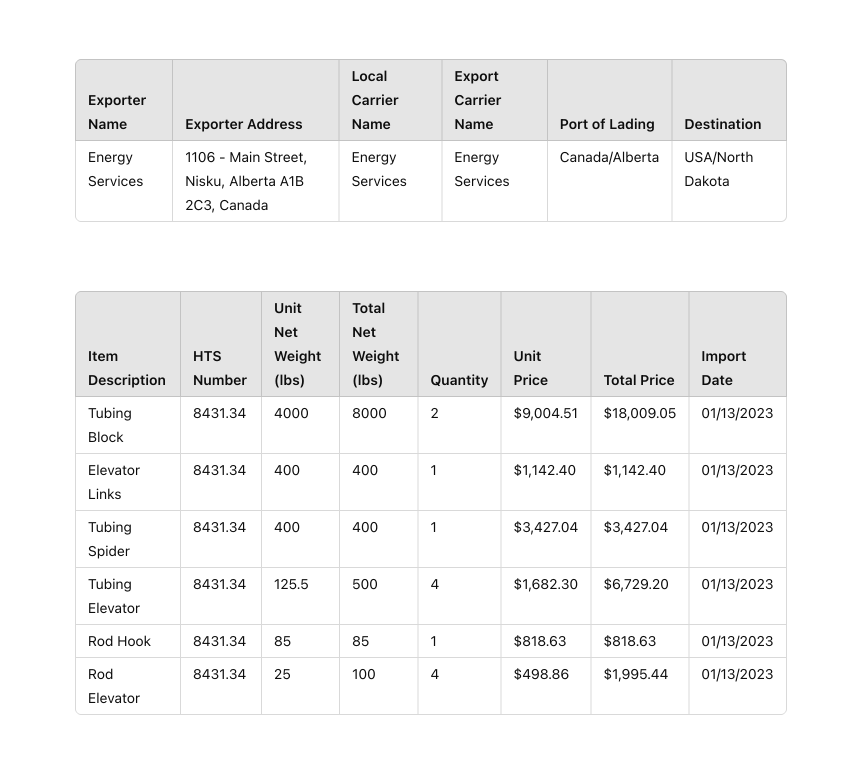
Now the beauty in Reform is that you can set up reusable shapes that you can apply to different documents. You can also set up workflows that automate end-to-end processes involving documents like populating your TMS, your internal database, reconciling invoices, and many other use cases that we’ll dive into in our upcoming articles.
So the next time you catch yourself manually copying and pasting data from a PDF into a spreadsheet, remember there’s a better way. Stop sitting on your data and start acting on it with Reform.
Want to learn more? Click here to book a personalized demo.
AI-powered Automations For Your Logistics Business
